Using Jira Plans in Agile way
Adjusting plan to meet deadlines on paper and aligning works to see how they fit within the timeline are two contrasting approaches.
In 2023, Atlassian made significant changes to the interface and calculation logic of Jira Plans, removing the ability to calculate the duration of average epics based on team capacity, average epic size in user stories, and average story points per ticket. Atlassian has no plans to revert these changes, making the Plans tool highly flexible, allowing users to customize it according to their preferences. While this flexibility is beneficial for project management Gantt tables, where users often believe they can figure things out better than statistics and existing workflow, in agile methodologies, transparency and truth are valued. Agile teams seek to understand how projects align based on statistics, enabling them to provide feedback on deadlines and manage MVP scope effectively.
I’ve decided to put together a brief explanation how we could still use Jira Advanced Plans workflow for fitting our needs (It seems to be a workaround, because Atlassian by themself could not provide me any working solution). //images etc is still to come
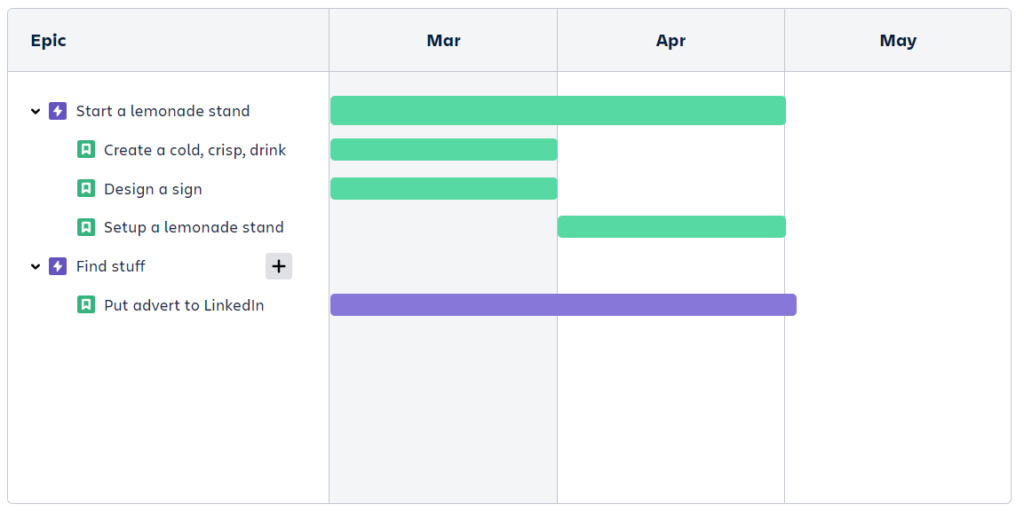
The principle we got used to within good-old Roadmaps and old interface of Plans, using average story points and letting Jira calculate the average size of an epic (we configured average number of tickets in an epic, as you probably remmember) – is actually “legacy”/bias. What we actually need, is to configure the average epic size. It doesn’t require us to “estimate” each ticket – we shouldn’t be interested in the location of each individual ticket on the board (although it provided us with some good insights about how “broken” our backlog is) – the forecast can’t be that precise; it would be deceiving ourselves. So, it’s enough to manually assign a score directly to the epic according to our statistics. Since there shouldn’t be too many epics in the backlog, it’s not a problem (otherwise, the question is about our backlog management, not Jira competence – it’s just another area that Jira now highlights). The most complicated part is not to lie to ourself during measuing the statistics and using them.
When I seeked for the solution, for me other side of the problem was how to distinguish between “default rated” and “actually rated” work. Nut now, when we set the average size, we do it at the epic level, which isn’t actually creating a problem for refinements (we refine user stories, right?). One more thing – in Plans, under View settings, there’s an option called “Roll-Up others” (Show a roll-up of sprints, releases, teams, and estimates in the fields section), which brings the predetermined score together with the sum of the actual estimate values of the tickets under the epic into the same field. Based on this, it can be seen whether we already have a better understanding of the epic and whether we should manually remove the value. Yes, this is now manual work, but not overkill.
This is how the calculation works. Currently, the only unclear question for me is how Jira places epics on the roadmap if there should be several in progress at the same time. The team’s throughput and performance configuration remain the same. In the past, Jira knew that if a team had 10 members, it could put 10 items into work in parallel. Currently, it also does this correctly at the ticket level. It’s not clear how Jira does this for empty epics (in the past, Jira knew how many tickets there probably were in an epic and could plan the epic accordingly). However, planning seems to be more or less adequate (Comparing old interface and new interface visualisations – they seem to be comparable. It should be noted that the top of the backlog has changed slightly between comparing moments, so I could not compare 1:1).
In the end, “More or less” is what we actually hope to get. It’s not much better that weather forecast – it supports your plannings and monitroing, but not predicting the absolute end-point. So, it’s fair enough.
Feel free to contact me on LinkedIn and ask additional questions